
As mentioned in our post on the challenges associated with refactoring legacy code, automation of refactoring is possible if you have:
The even-better news – these capabilities already exist today – they’re called transpilers, but probably not the transpilers you’re thinking of.
When most developers think of transpilers, they think of static, rules-based transpilers which struggle because (1) implementation differences create interdependencies that aren’t linear, so the volume of rules necessary to solve them become exorbitant, (2) the pace of change of modern languages is difficult for rules to keep up with.
But there is another class of transpilers – that use a tertiary language as an intermediary. Tertiary languages abstract logical constructs and decouple source and target languages, creating a bridge that allows for more generalized mappings and dynamic handling of implementation differences. Transpilers that use a tertiary language as an intermediary not only avoid the issues caused by static rules, but - by the very nature of their structure - perform more accurately, and improve performance more quickly. It is for this reason that many researchers in the Generative AI space are adopting this technique to enhance their models (which still don’t outperform transpilers). See here, here and here.
In this post, we’ll explain in more detail how tertiary language-based transpilers work, and why their very structure makes them so well-suited to refactoring legacy code to modern code.
The first step for most transpilers is to convert the source code into an Abstract Syntax Tree (AST), which represents the structure of source code in a hierarchical, language-neutral format.
Here’s an example of a simple Java program:

And here is the AST that represents the structure and logic of the program in a hierarchical format:

What you notice from this is that the use of an AST ensures the functional intent of the original code is preserved during legacy code refactoring. This is a critical benefit of transpilers that is missed by Generative AI (at least for now), and creates real risk in manual refactoring when code is not fully documented.
Now, here is an identical program in COBOL:
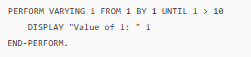
And here is the AST that represents the structure and logic of the COBOL program in a hierarchical format:

While the code for COBOL and Java look very different, the ASTs for COBOL and Java look a lot more similar to one another, having the same logical structure:
This consistency enables the intermediary representation (AST) to serve as a bridge between COBOL and Java, facilitating accurate refactoring of legacy code.
While an Abstract Syntax Tree (AST) effectively addresses the challenge of decomposing legacy source code into its logical structure, a tertiary language goes a step further by solving four additional challenges:
1. When 1:1 Data Type and Function Mappings Exist
When legacy source code includes constructs that map directly to equivalent features in modern languages, a tertiary language operates similarly to a static, rules-based transpiler. While the tertiary language ensures that functionality is preserved, it also offers the opportunity to incorporate additional layers of logic. This can include handling unique requirements, accommodating differences in language capabilities, or optimizing for specific runtime behaviors. This added flexibility is critical for handling edge cases, optimizing performance, and addressing specific project requirements that fall outside the scope of simple mappings. Here are a few examples:
Handling Edge Cases
A static transpiler might fail to account for edge cases, such as variable type mismatches or nuanced error handling. A tertiary language allows for incorporating these considerations, ensuring robust output.
Customizable Mappings
The tertiary language can adapt mappings to project-specific requirements, such as using alternative libraries or constructs for better performance or maintainability.
2. Addressing Capability Gaps
Legacy source code often includes features or constructs that lack a direct equivalent in modern languages. These capability gaps can arise from differences in data types, native functions, or built-in language features. A tertiary language bridges these gaps by abstracting the functionality into a neutral, logical representation, enabling the transpiler to map these features to equivalent or custom implementations in the target language.
This approach ensures that the original intent and functionality are preserved, while providing flexibility to accommodate differences in language capabilities or project-specific needs. Here are a few examples:
Handling Capability Gaps in Legacy Data Types
A tertiary language enables abstraction of unique data types from legacy languages, such as COBOL’s packed decimals (COMP-3), which are not natively supported in modern languages like Java.
This abstraction also allows the transpiler to handle variations, such as regional differences in number formatting or the need for rounding rules, without adding complexity to the source or target code.
Customizing Functionality for Project-Specific Needs
Capability gaps in native functions, like COBOL’s built-in SORT statement, can be bridged through a tertiary language. Instead of relying on boilerplate code to replicate the function, the tertiary language provides a framework to map the intent of the operation.
This customization ensures the refactored code performs optimally for the specific use case, whether it’s handling small datasets in memory or scaling to large, file-based operations.
Scalability and Maintainability
Static transpilers often require extensive rule sets to handle capability gaps, which can become unmanageable as languages and projects evolve. A tertiary language simplifies this by centralizing the abstraction of these features.
3. Bridging Drastic Differences in Implementation Styles
Legacy and modern programming languages often approach the same tasks—such as looping, memory management, or error handling—in vastly different ways. These implementation style differences arise from the distinct paradigms of procedural languages like COBOL and object-oriented or functional languages like Java. A tertiary language bridges these differences by abstracting the logical intent of the implementation, enabling the transpiler to map it to the most appropriate construct in the target language.
This abstraction ensures that the underlying functionality is preserved, while allowing the refactored code to align with the design principles and best practices of the modern language. Here are a few examples:
Aligning Control Flow Constructs
Legacy languages like COBOL often rely on procedural constructs such as PERFORM loops or GO TO statements, which can result in less structured and harder-to-maintain code. Modern languages like Java, however, emphasize structured programming with scoped loops and conditionals.
This approach avoids translating legacy constructs into unstructured or error-prone patterns, making the refactored code cleaner and easier to maintain.
Adapting Memory Management Approaches
Legacy languages often rely on static memory allocation, with variables persisting throughout the program's execution unless explicitly reset. Modern languages, by contrast, use dynamic memory allocation and garbage collection, requiring scoped variables and objects.
By bridging these differences, the tertiary language ensures memory handling is refactored in a way that fits the modern language's paradigm without introducing memory leaks or unnecessary complexity.
Whether it's unstructured control flows, manual memory management, or outdated error-handling patterns, a tertiary language enables the transformation of legacy implementations into clean, modern equivalents. This makes it an essential tool for bridging the gap between old and new programming paradigms.
4. Leveraging Context-Aware Processing for Intent Inference
One of the most complex challenges in refactoring legacy code is understanding the intent behind the original implementation. Legacy systems often lack proper documentation, rely on implicit behaviors, and contain tightly coupled logic. Static, rules-based transpilers struggle to infer this intent, as they operate purely on syntax without understanding the broader context of the program.
A tertiary language, combined with context-aware processing, goes beyond static mappings by embedding metadata and semantic analysis to infer the functional intent of the code. This approach ensures that the refactored system preserves not only functionality but also aligns with the original purpose of the code, even in complex, undocumented cases.
How Context-Aware Processing Works
Context-aware processing analyzes the relationships and dependencies within the source code, enabling the transpiler to:
This deeper understanding allows the tertiary language to generate accurate, intent-preserving mappings in the target language.
Examples of Context-Aware Processing
Legacy languages like COBOL frequently use global variables that are shared and modified across multiple sections of the program. Refactoring these variables into a modern language requires understanding their scope, lifecycle, and dependencies.

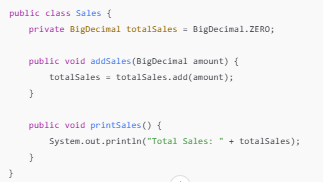
In legacy code, it’s common for multiple operations to rely on shared resources or tightly coupled workflows. Context-aware processing disambiguates these overlaps, identifying separate logical units and translating them into modular constructs.

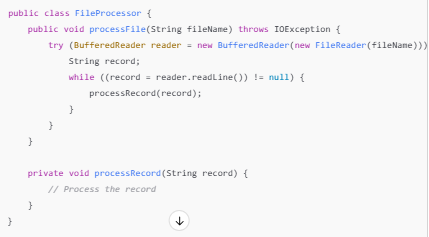
Context-aware processing, powered by a tertiary language, enables legacy code refactoring to move beyond syntax and semantics into true intent preservation. This capability ensures that even the most complex and undocumented legacy systems can be transformed into clean, modern code without losing their original purpose or functionality.
By leveraging Abstract Syntax Trees to decompose source code into a logical structure, tertiary languages build upon this foundation to provide:
These capabilities not only simplify the transition from legacy systems but also produce code that is modular, maintainable, and aligned with modern best practices.
The challenge of legacy code refactoring is no longer a question of “if” but “how effectively.” Tertiary language transpilers provide a clear path forward, enabling organizations to modernize their systems while preserving critical functionality and intent. By adopting this approach, CTOs and development teams can unlock the potential of their legacy systems and position themselves for a more agile, future-ready technology stack.
Are you ready to transform your legacy code? Explore the power of our tertiary language transpilers and take the first step toward seamless modernization.