
Refactoring legacy code is difficult – whether it is done manually, or you try to automate it. To understand why refactoring code is so difficult, we need to start by understanding the 4 major components of a programming language:
While programming languages share many fundamental concepts, there are also critical differences. Legacy languages often implement these components in simpler, procedural ways, whereas modern languages emphasize modularity, abstraction, and advanced capabilities. These differences form the foundation of the challenges faced when refactoring code, and fall into three categories:
Let’s go through a few specific examples of native capability differences and implementation differences that illustrate the complexities of automated refactoring.
Data type mismatches: COBOL has packed decimals (COMP-3) for precise fixed-point arithmetic. Modern languages like Java lack native support and require the use of BigDecimal. This data type mismatch requires additional handling, such as defining precision and scale, which could lead to errors if not done correctly.
COBOL: The value 12345.67 is stored in a compact binary-coded decimal format, with two decimal places
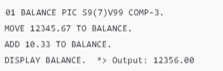
Java: To handle precise decimal arithmetic, Java relies on the BigDecimal class, which is not a native data type but part of the java.math library

Function mismatches: COBOL has a native SORT statement to handle file-based sorting directly within the language, while Java requires developers to implement sorting manually or use library-based solutions.
COBOL directly sorts a file based on a specified key without additional code.
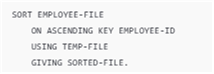
Java requires significantly more boilerplate code to achieve the same result. This gap makes direct mapping impossible and often leads to increased complexity when refactoring.

Global variable handling: In COBOL, global variables are often shared across multiple procedures, creating hidden dependencies. During refactoring, you must identify every place where a variable is read or written to ensure equivalent functionality in Java. This requires extensive analysis. Additionally, in COBOL, variables persist throughout the program’s execution unless explicitly reset. In Java, variables are typically created and destroyed dynamically, requiring careful management of their lifecycle to avoid memory leaks or unintended data loss.
Procedural constructs: COBOL’s control flow relies heavily on procedural constructs like GO TO, which can make the program flow less structured and harder to trace. Modern languages enforce structured programming principles, which discourage goto-style jumps and rely on clearly scoped loops and conditionals. Refactoring COBOL’s GO TO and procedure-driven logic into Java’s structured approach requires analyzing the entire program flow to avoid introducing unintended side effects.
COBOL

Java
The good news is that most syntactical, grammatical, and capability (data type, function) differences can be addressed with static, rule-based mappings. The bad news is that implementation differences are significantly harder to resolve. These differences are deeply tied to how a language handles variables, memory, and control flow—all of which are interdependent. Properly refactoring through implementation differences requires understanding the entire logical structure of a program and inference of intent to ensure functionality is preserved.
So is the automation of refactoring a lost cause? The short answer is “No!” Automation of refactoring is possible if you have:
The even-better news – these capabilities already exist today – they’re called transpilers, but probably not the transpilers you’re thinking of.
When most developers think of transpilers, they think of static, rules-based transpilers which struggle because (1) implementation differences create interdependencies that aren’t linear, so the volume of rules necessary to solve them become exorbitant, (2) the pace of change of modern languages is difficult for rules to keep up with.
But there is another class of transpilers – that use a tertiary language as an intermediary. Tertiary languages abstract logical constructs and decouple source and target languages, creating a bridge that allows for more generalized mappings and dynamic handling of implementation differences. Transpilers that use a tertiary language as an intermediary not only avoid the issues caused by static rules, but - by the very nature of their structure - perform more accurately, and improve performance more quickly. It is for this reason that many researchers in the Generative AI space are adopting this technique to enhance their models (which still don’t outperform transpilers). See here, here and here.
If you’d like to learn more about how tertiary language-based transpilers work, click here.