1. Introduction
Neural Machine Translation (NMT) models, a specialized form of Large Language Models (LLMs), have revolutionized natural language translation. From converting English to Spanish to decoding complex medical texts, these models leverage advanced transformer architectures to understand and translate language with remarkable accuracy. Inspired by this success, developers and researchers have explored applying these models to a different challenge: refactoring legacy code.
Legacy applications, particularly those written in languages like COBOL, represent a critical but aging backbone of industries such as banking, insurance, and government. Modernizing these systems into languages like Java or Python is a pressing priority, but the process is notoriously complex, time-consuming, and risky. Given the parallels between human languages and programming languages, it’s natural to wonder: Could AI-driven automation reduce the time and cost of legacy application modernization?
The idea is compelling—automated, AI-driven refactoring of legacy code could drastically reduce the time and cost of modernization efforts. However, as we’ll explore in this post, there are significant limitations to using NMT models for this purpose. These challenges highlight both the unique complexities of legacy code and the inherent constraints of transformer-based architectures.
Despite these hurdles, NMT models still have a role to play in the modernization journey. At RecodeX, we’re actively exploring how to leverage NMT innovations as part of a broader strategy to tackle legacy application modernization. In this post, we’ll dive into the structure of NMT models, the specific challenges they face with legacy code, and how we’re working to address these issues in partnership with forward-thinking clients.
2. How Neural Machine Translation Models Work
Neural Machine Translation (NMT) models, such as those used in Google Translate, rely on advanced machine learning techniques to convert input from one language to another. At their core, these models use a transformer architecture, which has become the standard for modern AI language systems due to its remarkable efficiency and accuracy. Here’s a high-level overview of how they work:
The Transformer Architecture
- Tokenization:
Before translation begins, the input (whether it’s natural language or code) is broken down into smaller units called tokens. For programming languages, this could mean breaking a line of COBOL into keywords, variables, operators, and other elements. - Embeddings:
Each token is converted into a numerical vector that represents its meaning in a high-dimensional space. These embeddings capture relationships between tokens, allowing the model to understand context and patterns. - Attention Mechanism:
Transformers leverage a mechanism called attention, which allows the model to focus on the most relevant parts of the input when generating an output. For example, when translating a COBOL PERFORM statement into a Java for loop, the attention mechanism helps the model focus on the loop’s initialization, condition, and body. - Sequence-to-Sequence Learning: The input tokens are processed in sequence, and the model generates a corresponding sequence of output tokens in the target language. This process is guided by patterns the model has learned during training.
Applying NMT to Programming Languages
NMT models treat programming languages as structured text, identifying patterns and relationships in code, much like they do for natural languages. For example:
- A COBOL ADD statement might translate directly into a Java += operation.
- A COBOL DISPLAY statement might map to a Java System.out.println() call.
While this approach makes NMT models promising tools for refactoring legacy code, the complexities of legacy applications reveal limitations that go beyond simple pattern matching. In the next section, we’ll explore these challenges, including dataset limitations, structural constraints, and hallucination risks.
3. Challenges in Refactoring Legacy Code with NMT Models
While Neural Machine Translation (NMT) models have shown promise in translating natural languages, applying them to legacy programming languages like COBOL comes with significant challenges. These limitations stem from the unique nature of legacy applications, the structure of NMT models, and the lack of robust training data. Let’s explore these challenges in detail.
3.1 Lack of Comprehensive Open Source Datasets
Neural Machine Translation (NMT) models depend on large datasets to learn the syntax, semantics, and patterns of a language. In natural language translation, open-source datasets abound, containing everything from classical literature to informal conversations, providing a rich foundation for model training. Unfortunately, the same ecosystem of open-source data does not exist for legacy programming languages like COBOL, creating significant barriers for accurate translation.
Challenges of Data Scarcity
- Scarcity of COBOL-to-Java Data
Unlike natural languages, where vast datasets exist for virtually every conceivable language pair, COBOL-to-modern-language datasets are limited, fragmented, or entirely unavailable. Publicly accessible collections of COBOL code rarely include corresponding translations in Java, Python, or other modern languages.- Impact:
- Without parallel datasets, NMT models struggle to establish relationships between COBOL constructs (e.g., PERFORM or COMP-3) and their equivalents in modern languages (e.g., for loops or BigDecimal in Java).
- This lack of data prevents models from learning the nuances of COBOL’s syntax and semantics, leading to inaccurate or incomplete translations.
- Example:
A dataset with COBOL’s SORT statement and its equivalent implementation in Java (Collections.sort()) could teach the model how to handle file-based operations in COBOL. However, the absence of such datasets leaves models to rely on generic patterns that may not apply to specialized COBOL logic.
- Limited Availability of Real-World COBOL Applications
Many COBOL applications are proprietary, handling sensitive data for industries like finance, insurance, and government. Organizations rarely share this code publicly due to security and confidentiality concerns.- Impact:
Proprietary codebases remain siloed, leaving researchers and developers with little access to diverse examples of real-world COBOL implementations.
Domain-Specific Challenges
- Highly Specialized Use Cases
COBOL’s primary domains—financial systems, banking operations, and government applications—introduce unique, domain-specific behaviors that are difficult to generalize. These nuances are often poorly documented, and existing datasets fail to capture them.- Impact:
Even if general-purpose COBOL datasets were available, they would not sufficiently represent the domain-specific rules, data formats, and workflows essential for accurate translation. - Example:
A COBOL program calculating compound interest might rely on specific rounding conventions, while its modern equivalent in Java must adhere to financial standards like IEEE-754 rounding. Without domain-specific training data, the model cannot account for these subtleties.
- Legacy Practices in COBOL Codebases
Many COBOL systems contain decades-old coding practices, workarounds, and custom logic introduced by different developers over time. These idiosyncrasies are unlikely to appear in the limited datasets that do exist, further complicating model training.
Example:
A COBOL program using a WORKING-STORAGE section for pseudo-global variables might implement unique naming conventions or ad-hoc data structures. Without exposure to such patterns, an NMT model is unlikely to recognize or replicate them correctly.
Potential Solutions
While the scarcity of COBOL-to-modern-language datasets is a major challenge, efforts to mitigate this issue are underway:
- Synthetic Data Generation:
By creating synthetic datasets that mimic real-world COBOL programs and their modern equivalents, researchers can provide NMT models with the training material they need. - Tertiary Language Representation:
Leveraging tertiary languages to abstract COBOL logic into a neutral form can reduce the dependence on large datasets by enabling more generalized mappings. This tertiary language acts as a synthetic dataset.
The lack of comprehensive open-source datasets is a significant obstacle for NMT models in refactoring legacy code. In the next section, we’ll examine another challenge: how memory limitations and contextual blindness affect the ability of NMT models to handle large, interconnected COBOL programs.
3.2 Limited Understanding of Contextual Dependencies
Legacy application frequently contain tightly coupled logic, implicit dependencies, and unstructured control flows that are difficult to infer. NMT models, which excel at translating well-structured text, often fail to account for these complexities. While self-attention mechanisms—a core feature of transformer-based architectures—improve a model’s ability to understand relationships within a limited context, they fall short when addressing the global interdependencies inherent in large legacy applications.
How Self-Attention Helps
Self-attention mechanisms allow NMT models to:
- Capture Local Context: By weighing the importance of tokens relative to each other, self-attention helps models track dependencies between nearby operations, such as variable declarations and their usage within a local scope.
- Identify Patterns: In structured segments of code, self-attention enables the model to identify relationships between constructs like loops, conditionals, and variables.
However, these benefits are constrained by the token limit of transformer architectures, which restricts the amount of code a model can analyze at once.
Memory Limitations of Transformer Architectures
Most transformer-based models, including the most advanced Large Language Models (LLMs), have a token limit of approximately 32,000 tokens—roughly 1,000 lines of code. This is far below the size of many legacy COBOL programs, which often span 50,000–250,000 lines or more.
- Impact of Token Limits:
Legacy applications are highly interconnected, relying on global variables, shared states, and long-range dependencies. When programs are larger than the token limit, they must be split into smaller chunks, leading to fragmented translations that often miss critical interdependencies.
Challenges Created by Contextual Blindness
- Global Dependencies Across Code Segments:
Legacy applications, especially those written in COBOL, often rely on global variables declared at the beginning of the program but modified and referenced in distant sections. When sections of the code are split due to token size limitations, the model cannot track the full lifecycle of these variables, leading to incomplete or inaccurate translations.
Example:
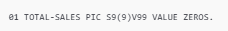
- Modification (Hundreds of Lines Later):

- Reference (Thousands of Lines Later):

To accurately refactor this program into a modern language like Java, the model must preserve the variable’s lifecycle and interdependencies across all these segments. Without a holistic view, critical updates or references may be missed.
- Implicit Logic and Coupled Flows:
COBOL programs often rely on implicit behaviors, such as side effects from previously executed sections or tightly coupled control flows. These dependencies are rarely documented, making them difficult for NMT models to infer. For instance, a PERFORM statement might depend on global variables updated in prior sections, which are out of the model’s context window. - Fragmentation of Translation:
Splitting programs into smaller chunks for token processing disrupts the program’s logical flow. Without access to the complete codebase, NMT models cannot resolve interdependencies across chunks, resulting in translations that fail to function correctly as a whole.
Why This Matters
The combination of token limitations and the contextual blindness they create underscores a critical limitation of NMT models: their inability to process legacy applications holistically. While self-attention mechanisms enhance context-awareness within a single chunk of code, they do not resolve the challenges of global dependencies or fragmented program logic.
Adding self-attention mechanisms, like those used in transformer models, improves context-awareness within a defined scope of tokens, but it does not directly address the fundamental memory limitations or contextual blindness inherent to transformer architectures when dealing with very large inputs, such as lengthy legacy programs.
Here’s how self-attention mechanisms help and where they fall short:
How Self-Attention Helps
- Improved Context Awareness (Within Token Limit):
Self-attention mechanisms allow models to weigh the importance of each token relative to every other token in the sequence. This helps the model understand dependencies between tokens within its token limit (e.g., global variables or nested loops within 1,000 lines of code).- Example:
In COBOL, a variable declared at the beginning of a program but used hundreds of lines later can still be accurately interpreted if both references fall within the token window.
- Flexibility in Understanding Relationships:
Unlike earlier sequence models (e.g., RNNs or LSTMs), self-attention can focus on long-range dependencies within the token window. For instance, in a large function, the model can connect a variable’s declaration to its usage, improving its ability to preserve the intent of the logic.
Where Self-Attention Falls Short
- Token Limitations Remain:
Transformer models, even with self-attention, are still limited by their maximum token size (e.g., ~32,000 tokens). While self-attention excels at understanding context within this window, it cannot analyze dependencies beyond the token limit. For legacy programs that often span 50,000–250,000 lines, critical interdependencies across distant sections of the code are lost. - Global Context Is Fragmented:
In legacy applications, critical interdependencies are often spread across different parts of the program. For example:- A global variable defined at the start of the program might be updated and referenced in separate sections spread across tens of thousands of lines.
- Self-attention mechanisms cannot "see" these relationships if they span multiple token windows, leading to contextual blindness.
- Memory and Computational Overhead:
Self-attention mechanisms are computationally expensive because they scale quadratically with the input size. Extending the token limit to cover entire legacy programs would demand prohibitively large memory and computational resources, making it impractical. - Implicit Dependencies in Legacy Code:
Legacy programs often rely on implicit behaviors, undocumented logic, and dynamic interactions that go beyond simple token-to-token relationships. Self-attention alone is not sufficient to infer the intent behind such complexities.
Potential Solutions to Memory Limitations and Contextual Blindness
- Hierarchical Attention Models:
Hierarchical models split the input into smaller chunks (e.g., functions or modules) and apply self-attention at both the chunk level and the global level. This can extend the context window while maintaining computational efficiency.- Example: Treating individual COBOL sections as separate "documents" and then summarizing their interactions.
- External Memory Mechanisms:
Enhancements like memory-augmented neural networks or retrieval-augmented generation (RAG) allow the model to refer to an external knowledge base, enabling it to "remember" dependencies across a broader scope. - Token Compression or Summarization:
Preprocessing techniques could summarize sections of code into abstract representations (e.g., through an Abstract Syntax Tree) before feeding them into the model. This reduces token count while preserving logical relationships. - Hybrid Approaches with Tertiary Languages: Using a proven tertiary language to abstract the program logic into modular components could complement self-attention by focusing on logical structure rather than raw token sequence
3.3 Risk of Hallucination
One of the most well-documented challenges with Large Language Models (LLMs), including those used for Neural Machine Translation (NMT), is their tendency to "hallucinate." Hallucination occurs when the model generates outputs that are plausible-sounding but incorrect or entirely fabricated. While this issue can be problematic in natural language translation, its consequences are particularly severe in the context of legacy code modernization, where precision and correctness are critical.
Why Hallucination Happens
- Incomplete Context:
NMT models rely on patterns learned during training, but when faced with incomplete information—such as undocumented code or ambiguous logic—they often "guess" what might be appropriate rather than recognizing the lack of clarity. - Overconfidence in Output:
LLMs generate outputs probabilistically, meaning they produce the most likely answer based on their training data. However, this does not guarantee correctness, especially when gaps in the training data or logic occur. - Lack of Ground Truth:
Legacy systems frequently contain implicit behaviors or ad-hoc solutions that are unique to specific implementations. Without explicit documentation or examples, the model has no "ground truth" to anchor its understanding, increasing the likelihood of hallucination.
Impact on Legacy Code Refactoring
When hallucination occurs during the refactoring of legacy code, it can lead to outputs that are plausible in syntax but deviate significantly from the original intent. This introduces significant risks, including:
- Incorrect Logic Implementation:
The model may generate code that appears functional but fails to replicate the behavior of the original program, potentially causing errors in critical systems. - Introduction of Non-Existent Functionality:
In some cases, hallucination results in the creation of functionality that does not exist in the source code, leading to unpredictable outcomes. - Compromised System Reliability:
Errors introduced by hallucination may not be immediately evident, especially in large, complex systems. This can lead to reliability issues in production, undermining trust in the modernization process.
Mitigating Hallucination Risks
- Human Review and Validation:
All model-generated translations should undergo rigorous review by experienced developers who can identify and correct hallucinated outputs. - Enhanced Training Data:
Expanding the training dataset with real-world COBOL-to-modern-language mappings reduces the likelihood of hallucination by providing more accurate patterns for the model to learn. - Incorporating Tertiary Language Representations:
A tertiary language provides a structured, logic-based intermediary that reduces reliance on guesswork. By abstracting the functionality of the source code, it ensures that translations are rooted in intent rather than probabilistic patterns. - Hybrid Approaches: Combining NMT models with tools like Abstract Syntax Trees (ASTs) or static rule-based systems can help ensure that the generated outputs remain logically consistent and grounded in the source code’s intent.
4. The Current State of NMT Use in Legacy Code Refactoring
Despite their limitations in fully refactoring legacy code into modern languages, Neural Machine Translation (NMT) models have found practical applications in areas where precision is less critical or where they work alongside human developers. These applications focus on assisting with documentation generation and acting as coding assistants, rather than attempting a fully automated transformation.
Here’s how NMT models are currently contributing to the modernization of legacy applications:
4.1 Automated Documentation of Legacy Code
One of the most significant challenges in legacy systems is the lack of comprehensive documentation. Over decades of updates, much of the original design intent behind COBOL programs is lost, leaving developers to rely on brittle codebases with limited guidance. NMT models have proven effective at generating documentation by analyzing the structure and functionality of code.
- How It Works:
NMT models parse legacy code and generate natural language summaries that describe the purpose of functions, variables, and workflows. This helps developers quickly understand the system and identify areas that need attention. - Example:
A COBOL program might include an undocumented PERFORM block that calculates loan interest rates. An NMT model could generate a summary like:
"This function calculates the interest rate for a given loan amount based on the duration and interest table stored in WORKING-STORAGE." - Benefits:
- Speeds up onboarding for developers unfamiliar with COBOL.
- Provides high-level overviews for business stakeholders to understand system functionality.
- Reduces the risk of introducing errors during modernization by clarifying intent.
4.2 Coding Assistants for Developers
Another promising use case for NMT models is assisting human developers during modernization projects. By working as coding assistants, NMT models can suggest snippets of code, refactoring options, or best practices based on input from the developer.
- How It Works:
Developers can input specific COBOL logic or functionality they wish to modernize, and the NMT model generates equivalent code in a modern language like Java or Python. While not perfect, this approach provides a starting point that developers can refine and integrate. - Example:
A developer might input a COBOL SORT statement and ask the model for a Java equivalent. The model could suggest a Collections.sort() implementation for in-memory sorting, which the developer can customize further based on the specific use case. - Benefits:
- Saves time by generating boilerplate code and suggestions.
- Helps bridge gaps for developers who are unfamiliar with legacy languages.
- Encourages consistency in legacy code refactoring by providing standardized patterns.
4.3 Accelerating Modular Modernization
While NMT models may struggle with translating entire legacy systems, they can be highly effective in translating small, self-contained modules. By focusing on isolated components of the code, models can generate accurate translations that developers can integrate into larger modernization projects.
- Example:
A COBOL program’s standalone report-generation module could be accurately translated into Java or Python by an NMT model, allowing developers to modernize smaller pieces of the system incrementally.
The Human-Plus-AI Paradigm
The current state of NMT use underscores an important truth: NMT models are most effective when augmenting human expertise, not replacing it. Their ability to document code, assist with snippets, and handle modular tasks makes them valuable tools in a developer’s toolkit. However, the human element remains critical for ensuring accuracy, handling interdependencies, and preserving the intent of legacy applications.
Looking Ahead
It is important to remember that today NMTs can achieve a 40-60% accuracy rate in refactoring legacy code like COBOL to modern languages like C or Java. NMT performance is significantly worse than tertiary language-based transpilers, which can achieve accuracy rates of 85-95%+ - and introduce many additional risks to the refactoring process, such as no guarantee of functional equivalence and hallucinations.
As you can see from the above, tertiary languages and Abstract Syntax Trees (ASTs) are likely to be crucial to the future NMTs. – essentially acting as a surrogate training data set and guidepost to the logical structure of the application. It is for this reason that many researchers in the Generative AI space are adopting this technique to enhance their models (which still don’t outperform transpilers). See here, here and here.
But you can’t just use any tertiary language or AST. These capabilities need to be comprehensive and well-tested in order to provide the backbone of accuracy necessary for NMTs. And therein lies the next limitation – only a few companies have tertiary languages and ASTs, and even fewer have tested and validated them against real-life legacy code. That’s where RecodeX comes in – our tertiary language and ASTs have been refined over 49 years, 2,000 clients and 300 million lines of client code.
We believe that innovation with NMT models has a vital role to play in solving the legacy application modernization challenge and are looking to partner with 1-2 clients to develop even more exciting, cutting-edge solutions. If you’d like to partner with us on this journey, contact us.
